Lessons Learned Putting a Thing on the Internet
This is a text version of a talk I gave on May 1st, 2017 at an event that my company hosted focusing on our experience bringing a connected device to market.
My talk focused on the software side of the company, presenting three lessons that we’ve taken to heart after two years in the trenches building a data-intensive hardware product. Slides available here.
At Whisker Labs, our goal is to unlock value from the electrical networks within homes.
 Fig. 1. Whisker Labs prototype device
installed on a circuit breaker panel.
Fig. 1. Whisker Labs prototype device
installed on a circuit breaker panel.
I bet you don’t often think about your home’s electrical system. We just turn stuff on and off as we go about our day. And yet, this system is implicit in practically everything that goes on in a home. It’s always there, and almost everything you do in your home has an effect on it. By putting a finger on this pulse, we’re able to provide a lot of value to homeowners and our partner organizations that they wouldn’t otherwise have access to.
The technology involved has two parts. We make a hardware product which monitors the home’s electrical network. And we run a SaaS platform which ingests, processes, and delivers insights from the data.
Lesson 1: Mind your protocols and queues
Software bridges the gap between these two parts of our business. This software spans multiple computational footprints, from embedded devices up to the machines in our cloud.
A good way to contextualize these tiers of software is to consider the time scales at which they operate.
 Fig. 2. Breakdown of the time scales at
eachstage of the data ingestion pipeline.
Fig. 2. Breakdown of the time scales at
eachstage of the data ingestion pipeline.
Time scales
Closest to the metal (literally), we have our sensors. These are custom PCBs that run interrupt-driven tasks on a low-power MCU. The sole purpose of the code running on these devices is to pull data out of magnetic field sensing elements at a rate of about 2,000 Hz, which translates to about 500 microseconds per polling operation.
These raw sensor data are put into a ring buffer with capacity equivalent to ⅒ of a second’s worth of data. Ten times per second, the sensors populate their output buffers with new data. It is then necessary for the sensors to be polled at a rate of at least 10 Hz, or else data will be lost.
In order to avoid hammering our backend, the agent which polls the sensors buffers data in order to space out transmissions to our API. By default, the transmission rate is 1 Hz, but can be modulated either to decrease end-to-end latency for important data or to implement exponential backoff in response to a backpressure signal from the API.
At this point, data has made its way into our backend. But the data itself consists of unitless signal measurements. Turning these raw data into meaningful measurements of current, voltage, and power requires a bunch of math and a learning process which, over time, calibrates its output according to characteristics of the magnetic field environment of the customer’s circuit breaker panel.
At the end of all this, we have output values in terms of scientific units that can be either displayed to customers or fed into further analysis workloads. The time scale at this “application layer” for our data tends to be on the order of seconds, or in the case of historical analyses, days, months, or years.
One consequence of this gradation of time scales is our reliance on queues, or more specifically, ring buffers. I often joke that our system is ring buffers all the way down, because it basically is when you think about it. The way each stage makes the jump to a higher time scale is to queue data until a threshold duration’s worth has been buffered, and then flush the buffered data to the next stage. Unbounded queueing being a recipe for memory leaks, we use ring buffers to fix our buffering capacity at each stage.
What I’m describing isn’t novel; It’s basically network programming 101. I’ll refer back to this in a later section.
Protocols
Another consequence that we’ve taken to heart is the fundamental importance of protocols, or the formats in which data are encoded and the policies enforced around interacting with it.
In the web universe, JSON is still the linga franca. Within datacenters, it’s increasingly common to pass data between services in more efficient formats, like Protocol Buffers or Thrift. In the scientific community, HDF is the standard, being better suited for numerical and tabular datasets.
One thing that I’m glad we did up front was to put thought into what data formats we want to support for exchanging data between the components outlined above. Each transition represents a different set of constraints in terms of memory, computation, and time. Additionally, we foresaw the need for our stream-processing pipeline to support types of data other than those produced by our sensors. For instance, we feed system metrics from our sensors and hub through the same APIs as energy data, letting the backend multiplex different data streams to the appropriate downstream services.
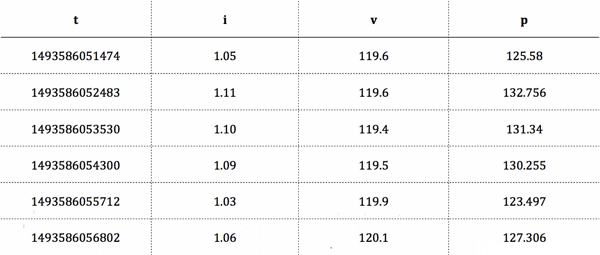 Fig. 3. Example of energy time series data at
a ~1-second interval.
Fig. 3. Example of energy time series data at
a ~1-second interval.
What we came up with is an extensible data model based on typed matrices. For any given type of data stream (“energy data”, “system metrics”, “thermostat data”), we can define a series of channels which each have a datatype and a unit. For example, we represent “energy data” as a matrix whose columns convey values like voltage in volts, current in amperes, and power in watts. “System metrics” streams convey the usual suspects (CPU/memory/network utilization) with added emphasis on measurements relevant to embedded systems, like temperature and line frequency.
In the memory and bandwidth-constrained environments of our devices, we use a custom binary protocol which enacts the matrix representation of our data model. This protocol is itself extensible too, allowing us to annotate payloads with metadata or implement new compression schemes in a backwards compatible way.
As an aside, this is the context in which we developed the adaptive averaging compression algorithm which I wrote about last year.
Being mindful of the protocols we use continues to pay dividends. By tailoring our data formats towards extensibility and our specific constraints, we’ve been able to drastically reduce data sizes, reduce the rate at which we produce technical debt, and streamline the process of integrating with external data providers.
Lesson 2: Err on the side of conservatism
A second lesson that we’ve learned is that production-grade embedded development requires a level of conservatism not fashionable in popular software culture.
This lesson is derived from the basic premise that we have no control over devices once they leave the factory. If the device installation process fails, there’s no crash-reporting system you can rely on for debugging. Once online, a device can disappear at any time should the homeowner’s power go out or they change their wifi password. Or the device’s network connection may slow to a trickle a few times per day because their breaker panel is on the opposite side of a wall as a microwave.
This throws a wrench in our ability as fleet operators to ensure timely data collection or reliable upgrades to the devices’ software. When you put a thing in someone’s home, you lose the ability to make any assumptions about its availability and serviceability.
The low-hanging fruit mitigation strategy is to enforce rigorous testing throughout the development process and thorough QA before devices leave the factory. This decreases the likelihood of self-inflicted wounds from bugs into our own software. But many risk factors are outside of our control. What if a critical open source library stops being maintained? What if a vendor on which you rely goes out of business?
Being a small team with tight shipping schedules, we may not be able to afford the sudden disappearance of a giant on whose shoulders we’ve stood. In contrast to a similar situation in the web development sphere, like migrating a user auth flow from Parse to Amazon Cognito, you can’t exactly swap out your device’s runtime with 100% confidence.
To de-risk our embedded software, we’ve erred on the side of conservatism when choosing to tie our ship to any outside entity. For instance, we’ve resisted the nascent trend towards running bleeding-edge containerization tools on our devices. On the one hand, being able to hermetically isolate processes would be a boon for security. But we’re not comfortable betting our devices’ decade-long operating requirements on open source projects that garner 100 commits per week.
Lesson 3: Everything old is new again
I am of the opinion that “IoT” is more marketing term than an indication of a fundamental shift in technology.
Looking out on the consumer landscape, we’re inundated in a sea of smart devices. Every appliance manufacturer under the sun is trying to sell us more expensive versions of their products that have screens or can send us text messages.
On the research end, if you read the literature on the Internet of Things, you’re vaulted into a near future in which our world is transformed by ubiquitous, networked sensors. No human desire or action is left unchanged. We are about to live in a Charles Stross novel.
After working with this stuff for a few years, I’ve started to wonder how the IoT trend will leave its mark on the software industry itself. I’m hopeful that as more developers work on or around connected devices, we’re collectively getting a chance to relearn how computers actually work.
In years past, the advance of Moore’s Law led to incrementally higher-level innovation in how software was developed and run. First we got structured programming and higher-level languages. Then operating systems and virtual memory. Then virtual machines.
As the Internet grew in the 90s we saw the rise of Java as a client-side platform. And then when that didn’t work out, JavaScript ascended. Now the browser is the lowest-level abstraction that many developers have to think about.
Provided the IoT sector finds its footing, this ever-present march towards higher-level abstractions will inevitably paper over many of the concerns of the underlying hardware and network topology. But I think we’re safe in assuming that for the next handful of years, the trend towards ubiquitous computing will rely on low-power hardware platforms that communicate under variable networking conditions.
 Fig. 4. Photo of Margaret Hamilton working on
an IoT product.
Fig. 4. Photo of Margaret Hamilton working on
an IoT product.
In a small way, these adverse characteristics harken back to the good ol’ days of programming at places like MIT’s AI Lab in the 60s or Bell Labs in the 70s. Working with resource-limited environments requires a fundamental understanding of how computers work. In all, this makes the space an enriching one to work in.
Vinyl records are resurgent and more people are having to care how many bytes their programs occupy in memory. Everything old is new again.
Conclusion
Throughout the lessons discussed above (the importance of protocols and buffering strategies, conservatism with respect to dependencies, and the value of the tried and true ways of doing things), an overarching theme emerges—there isn’t a “default path” one can take when building software for a connected device.
For many companies, there’s a well-trod path of battle-tested solutions to most problems that arise. Need a webapp? Use Rails or React. Website slow? Use Memcached or Redis. Deploys slow? Use Docker, I guess.
In the IoT world, you’re in less-charted territory. Your problems are more apt to be something fundamental, like how your device is using the network or how the time scales of operation align between devices or how your device is translating physical stimuli into a stream of numbers.
I, for one, relish these kinds of problems that require you to sink your teeth in. And I hope we as an industry use them as an opportunity to grow.
Thanks to Fikreab Mulugeta for reading and providing feedback on drafts of this essay.